
Bacterial Genetics and Genomics book Discussion Topic: Chapter 16, question 13
At the time of writing this blog many of us find ourselves at home due to the COVID-19 pandemic. This has necessitated a change in focus for our research; for many of us our research laboratories are closed and we are working from home, socially isolating in an effort to reduce transmission of the virus.
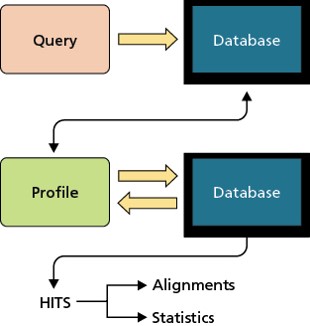
Investigations in bacterial genetics and genomics using bioinformatics tools can be conducted outside of the lab. This means that so long as you have an internet connection, you can do meaningful research and make meaningful discoveries. In Chapter 16 of Bacterial Genetics and Genomics, some of the tools that can be used to explore bacterial genes are introduced. At the end of this Chapter, Gene Analysis, the three Discussion Topics suggest some ways in which these tools can be explored. In this blog and the next few that follow, I will work through these three Discussion Topics as examples of some of the things that we can do at home and at our computers to do research and make discoveries outside of the lab.
First tool we are going to explore using is PSI-BLAST. This is one of the suite of BLAST tools, which enable us to search for DNA or protein sequences that are similar to our sequence of interest. This can tell us if there are other sequences similar to our sequence in the public databases, which might tell us something about the sequence. Unlike the other BLAST searches, PSI-BLAST looks for more distant relationships between sequences by searching for similar sequences and then using those similar sequences to search again and again. This can be useful when trying to track down protein sequences that are distantly related or when trying to find a function for a hypothetical protein that otherwise is only similar to other hypothetical proteins. Hypothetical proteins are how we designate the potential products from regions of DNA that look like they could possibly be genes, but which don’t share similarity to known proteins. Hypothetically, the stretch of DNA may be a gene that encodes a protein, but it doesn’t look like anything else other than perhaps other hypothetical proteins.
I am starting with a hypothetical protein sequence from some genome sequence data we are investigating in my research group. To keep track of the protein sequence, I have pasted it into a Notepad file and saved it in FastA format. I’m using Notepad because this means that there isn’t any extra formatting added to the file that might interfere with any of the analysis that I want to do. When I save the file it will just be saved as plain text. To make it FastA format, I add a line at the top that starts with the greater than symbol “>” followed by any identifying information I’d like. So my file look something like this at the beginning:
>Hypothetical protein for blog post analysis
MIKQIIEE….
I haven’t included all of the protein sequence here, but in total my protein is 614 amino acids.
Now that I have the sequence all I need to do is run it through PSI-BLAST. To do this I go to the NCBI website http://ncbi.nlm.nih.gov
At the right hand side of the page, under Popular Resources, is a link to BLAST. I follow this link to the BLAST page http://blast.ncbi.nlm.nih.gov/Blast.cgi
PSI-BLAST is a Protein BLAST, so the next click is on the blue box that says Protein BLAST, with the graphic of the protein alpha helix structure on it. This takes us to the BLAST suite page.
By default this is the standard protein BLAST, BLASTP. I want to use PSI-BLAST. To do this I scroll down the page a bit and find the radio buttons in the Program Selection section just above the blue BLAST button and be sure to select PSI-BLAST.
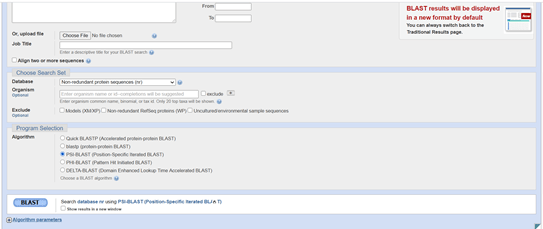
Having done that I will now fill out the rest of the form to be able to do my PSI-BLAST. At the top of the form it says enter Query Sequence. This is the sequence that I want to know more about. This is my hypothetical protein sequence. There are several options for how to enter or give BLAST access to the sequence information. I am going to put in the FastA sequence by doing copy-paste from my Notepad file. With the sequence pasted into the large box at the top there is nothing else I need to in the first section of the form. The next part of the form says Choose Search Set. I am going to leave this as the default, which is to search the non-redundant protein sequences database. I’ve already done the Program Selection, having chosen PSI-BLAST. I can tick the box at the bottom to say I want the results shown in a new window. This can be useful if you want to run several searches because you can reset the form and have your results appear in new windows when they are complete. To run the search press the blue button that says BLAST.
Depending on the time of day and how busy the servers at NCBI are, it can take some time to run your PSI-BLAST search (or any BLAST search). This is why it can be useful to have your search results show in a new window. You can then have the form available for doing more investigations while you wait.
The results screen has several tabs where the results of your search will be displayed. For PSI-BLAST, additional iterations can be run, which is the purpose of PSI-BLAST. It will find more and more distantly related similar sequences to those that you take from the list to select for PSI-BLAST second and third iteration searches.
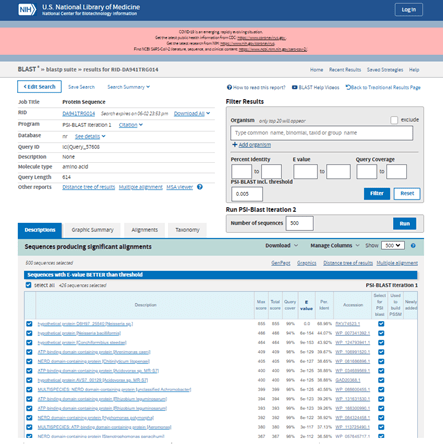
For my results the top three hits are other hypothetical proteins but further down the list is an ATP-binding domain-containing protein and a NERD domain-containing protein. I am able to select or restrict the number of sequences or specific sequences to include in iteration 2 of the PSI-BLAST. I can do this using the blue tick boxes for individual sequences or by entering the number of sequences to include in the box under the Run PSI-BLAST Iteration 2 heading. I’m going to leave this at the default 500 sequences and press the blue Run button.
Scrolling down through the results of the second iteration the table shows with ticks in green circles those that were used to do the first iteration in one of the columns. Those that are newly added have a green tick in a new column and are highlighted in yellow. This makes it easy to identify newly discovered proteins that are similar to my original protein.
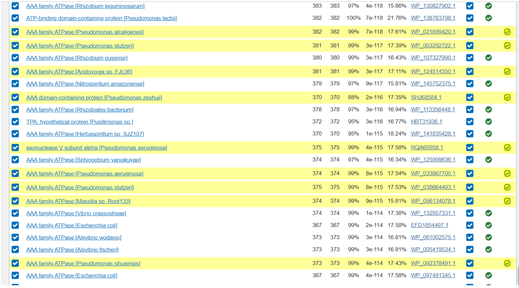
I have decided to try my luck and run a third iteration just to see what comes up. Some of the PSI-BLAST hits could be very dissimilar when we do repeated iterations, however we might also discover something interesting that could lead us to some insight. It is important that as scientists we critically assess the data in front of us. So once I collected the data, I’ll need to look at it and decide what contributions these results make to my understanding of the hypothetical protein.
At iteration three the new data is much further down the list and I can see that the similarity is much lower. The Query cover (the third column of numbers, expressed as a percentage) has gone from around 99% to around 68%. This means that less of the length of my protein is similar to these proteins. Also the Percent Identity is lower (the column of numbers before the hyperlink, expressed as a percentage) has gone very low, to the mid-teens. This means the proteins are not very similar. However, these proteins are all within a similar family to those previously recovered in iteration 2, which had higher coverage and a slightly higher Percent Identity score.
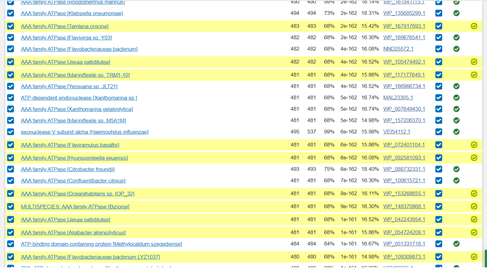
Therefore at the end of my PSI-BLAST research into my hypothetical protein of interest I have a few avenues for further investigation. My potential protein has similarity to sequences that contain ATP-binding domain-containing protein sequences and a NERD domain-containing protein sequences. In addition, it shares some limited homology with AAA family ATPases. Between the similarity to the ATP-binding domain-containing proteins and these, there might be some ATP dependent activity of my hypothetical protein, which I will need to investigate further.
I will now need to read about these domains and these types of proteins to be able to assess the outcome of my PSI-BLAST and decide what I’m going to do next with this information. I will also be sure to look at the data on the other tabs: Graphical Summary; Alignments; and Taxonomy, so see what more this view of the data can tell me. I might go back and re-run the PSI-BLAST and look at this detailed information at each iteration and possibly follow the links for specific proteins of interest to learn more.
